Docker学习笔记——DockerSwarm
概述
Docker Swarm是Docker引擎内置的容器编排工具,可以将多台Docker主机组成一个集群,统一调度和管理容器服务。
单机跑Docker够用,但到了生产环境——服务要多副本、要高可用、某台机器挂了容器得自动迁移——就需要把多台机器组成集群来调度。Docker Swarm就是Docker原生的集群编排方案,不需要额外装东西,docker swarm init一条命令就能把当前节点变成集群管理节点。
本篇记录Swarm的核心概念、集群搭建、服务管理、网络与负载均衡、stack部署,以及和Kubernetes的对比与K8s核心概念速览。Docker基础和Compose的内容已在《Docker基础篇》《Docker进阶篇》里讲过,这里不重复。
核心概念
节点(Node)
Swarm集群由多个Docker主机组成,每台主机就是一个节点,分两种角色:
- Manager节点:负责集群管理——接收用户命令、调度任务、维护集群状态(用Raft协议做一致性)。Manager同时也能跑容器任务。
- Worker节点:纯干活——接收Manager分配的任务,运行容器。
一个集群可以有多个Manager(建议奇数个,如3或5,保证Raft选举正常),其中一个是Leader,其余是备。Worker数量不限。
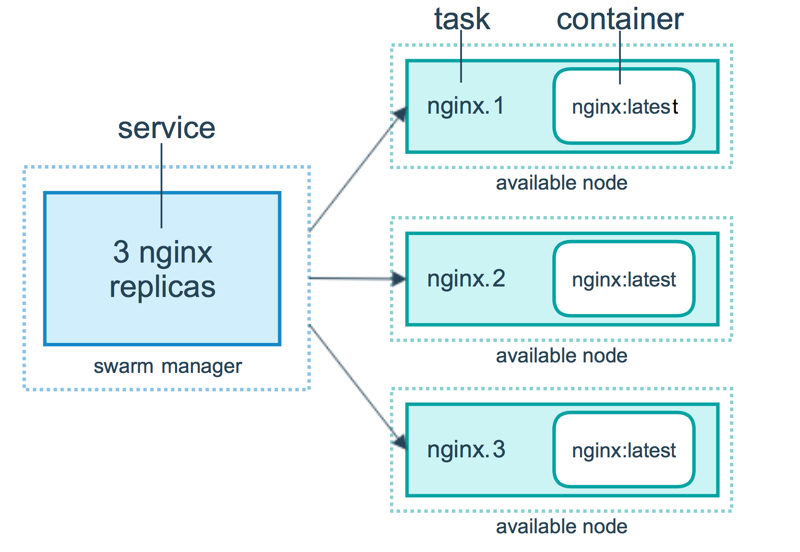
如下图所示,swarm 集群由管理节点(manager)和工作节点(work node)构成:
Leader 与 Raft 选举
多个Manager中只有一个是Leader,负责实际的调度决策和集群状态变更(创建/更新服务等)。其余Manager是Follower,同步Leader的状态,随时准备接替。
Leader选举靠Raft一致性协议,核心机制:
- 心跳:Leader定期向Follower发心跳,Follower收到就重置计时器。
- 选举触发:某个Follower超时没收到心跳,就认为Leader挂了,把自己变成Candidate发起投票。
- 多数派(Quorum):Candidate获得超过半数Manager的投票就成为新Leader。这就是为什么Manager数量必须是奇数——偶数个在网络分区时可能两边票数相等,谁也选不出来。
- 日志复制:所有状态变更先写入Leader的日志,Leader复制到多数Follower确认后才算提交。
Manager数量与容错:
| Manager数 | Quorum(多数派) | 可容忍故障数 |
|---|---|---|
| 1 | 1 | 0(单点,不推荐) |
| 3 | 2 | 1 |
| 5 | 3 | 2 |
| 7 | 4 | 3 |
不建议超过7个Manager——Manager越多Raft同步开销越大,写性能下降。大集群里Manager保持3~5个,其余全做Worker。
Leader挂了后选举通常在秒级完成,选举期间集群不能执行新的调度操作(如创建/更新服务),但已经运行的容器不受影响,继续正常服务。
服务(Service)与任务(Task)
这是Swarm里最核心的一对概念:
- Service:用户定义的”期望状态”——跑什么镜像、几个副本、怎么更新、端口怎么映射。Swarm的调度单位。
- Task:Service的一个执行实例,对应一个具体的容器。3个副本就是3个Task,分布在不同节点上。
关系:Service → 拆成多个 Task → 每个Task在某个节点上跑一个 Container。
栈(Stack)与栈名
Stack是一组相关Service的集合,用一个Compose文件(docker-compose.yml)声明,通过docker stack deploy一次性部署。《Docker进阶篇》里那个下载器服务栈示例,就是典型的stack用法。
栈名是docker stack deploy时指定的名字(如docker stack deploy -c xxx.yml my_stack里的my_stack),它的意义:
- 命名空间隔离:栈内所有资源(服务、网络、卷)都会自动加上
栈名_前缀。比如栈名my_stack里的web服务实际名称是my_stack_web,网络是my_stack_default。这样同一集群里可以部署多个栈,资源名不会冲突。 - 批量管理:
docker stack services my_stack、docker stack rm my_stack都是按栈名整体操作,不用逐个服务处理。 - 多环境部署:同一份Compose文件可以用不同栈名部署多套(如
dev、staging、prod),互不干扰。
部署模式
| 模式 | 说明 | 适用场景 |
|---|---|---|
replicated(默认) |
指定副本数,Swarm自动分配到各节点 | 大多数无状态服务 |
global |
每个节点跑且仅跑一个实例 | 监控Agent、日志收集器等需要每台机器都跑的 |
replicated-job |
指定总任务数和并发数,跑完即退出 | 批处理、数据迁移等一次性任务(Docker 20.10+) |
global-job |
每个节点跑一次,跑完即退出 | 全集群一次性操作(如清理脚本) |
replicated和global是常驻服务,容器退出会被重新拉起;*-job是一次性任务,跑完就算结束、不重启。
下面是一个 global 模式的真实示例(android-safe 安全检测服务):
1 | version: '3.7' |
这个服务用 deploy.mode: global,集群里每个节点都会跑且仅跑一个 android-safe 实例——新增节点时自动补一个,不用手动扩容。它还做了两件 global 服务常见的事:
ports: 8361:8361把端口发布出去,配合 Routing Mesh,从任意节点的 8361 都能访问到本机实例;volumes把宿主机的日志目录挂进容器,每个节点的日志各自落在本机磁盘上。
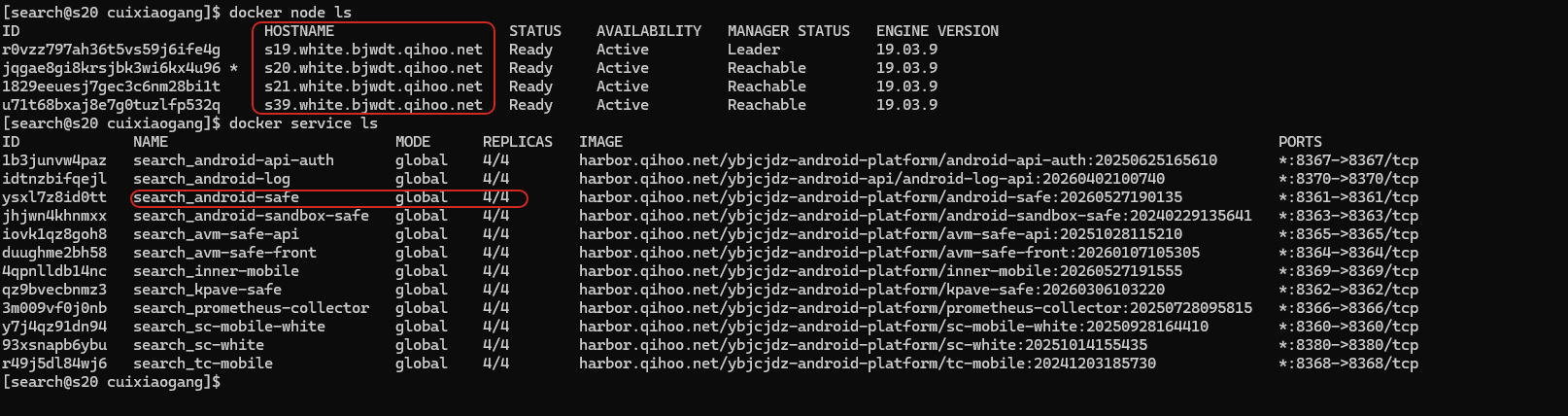
这正是「监控 Agent、日志收集器等需要每台机器都跑」的典型用法——每个节点一个实例、就近处理本机数据。
集群搭建与运维
初始化集群
在第一台机器上执行:
1 | docker swarm init --advertise-addr 192.168.1.10 |
--advertise-addr指定本节点的通信IP(多网卡时必须指定)。执行后当前节点成为Manager(同时也是Leader),命令输出会给出一条docker swarm join命令,里面带着加入集群用的token。
加入节点
在其他机器上执行上一步输出的join命令:
1 | 加入为 Worker |
Worker token和Manager token是不同的,分开管理。
查看集群状态
1 | docker node ls # 列出所有节点及角色、状态 |
节点可用性
| 状态 | 说明 |
|---|---|
active |
正常接收任务(默认) |
pause |
不接收新任务,已有任务继续运行 |
drain |
不接收新任务,已有任务迁移到其他节点。常用于维护前 |
1 | docker node update --availability drain <节点ID> # 维护前排空节点 |
异构节点与配置建议
实际环境中各节点的硬件配置未必一致,比如32C/288G和24C/64G混在同一个集群。Swarm的默认调度器不感知节点硬件差异——它只按”哪个节点任务少”来分配,不会自动把吃内存的服务调度到大内存机器上。这会导致几个问题:
- 内存不均衡:大内存消耗的服务可能被调度到64G的小节点上,直接OOM。
- CPU不均衡:计算密集型任务调度到小核机器上,性能下降。
- 难以预测:副本分布随机,每次部署结果可能不同。
应对方式:
| 方式 | 做法 | 说明 |
|---|---|---|
| 标签约束(推荐) | 给节点打标签,服务用--constraint绑定 |
最常用,精准控制 |
| 资源预留 | deploy.resources.reservations声明最低要求 |
Swarm会跳过资源不足的节点 |
| 配置统一 | 同一集群尽量用相同配置的机器 | 最省心,消除调度的不确定性 |
标签约束示例:
1 | 给大内存节点打标签 |
建议:同一集群尽量用相同配置的机器。配置一致时调度最简单、行为最可预测,不需要靠标签约束来弥补硬件差异。如果确实有异构节点,用标签把节点分组、服务用--constraint绑定到对应组,配合resources.reservations做兜底。
离开与解散集群
1 | Worker 离开集群 |
解散整个集群没有专门的命令——每个节点各自docker swarm leave,最后一个Manager用--force退出,集群就自然消失了。离开前记得先drain该节点,让上面的任务迁走。
服务管理
创建服务
1 | 创建一个 3 副本的 Nginx 服务,映射 80 端口 |
常用命令
| 命令 | 作用 |
|---|---|
docker service ls |
列出所有服务 |
docker service ps web |
查看服务的各个任务(哪些节点在跑、状态如何) |
docker service inspect web |
查看服务详细配置 |
docker service logs -f web |
查看服务日志(聚合所有副本) |
docker service scale web=5 |
扩缩容——把副本数调到5 |
docker service rm web |
删除服务 |
docker service scale可以同时调多个服务:docker service scale web=5 api=3。
滚动更新与回滚
更新镜像版本时,Swarm不会一次性替换所有副本,而是分批滚动替换:
1 | docker service update --image nginx:1.25 web |
更新行为可以在创建服务时或更新时配置:
| 参数 | 含义 |
|---|---|
--update-parallelism N |
每批同时更新N个副本 |
--update-delay 10s |
每批之间间隔10秒 |
--update-failure-action pause |
更新失败时暂停(还可选continue或rollback) |
--update-order stop-first |
先停旧的再起新的(默认),另一个是start-first |
如果更新出了问题,可以一键回滚:
1 | docker service rollback web |
这些参数对应的就是《Docker进阶篇》Compose示例里deploy.update_config下面的那些配置。
调度约束(placement)
控制服务的副本”往哪放”。命令行用--constraint和--placement-pref指定,Compose 文件里对应deploy.placement(见后面「deploy 配置项详解」)。
| 机制 | 参数 | 作用 |
|---|---|---|
| 约束(constraint) | --constraint 'node.role==worker' |
硬性条件——不满足就不调度 |
| 偏好(preference) | --placement-pref 'spread=node.labels.zone' |
软性策略——尽量均匀分散 |
常用约束条件:
| 条件 | 示例 |
|---|---|
| 节点角色 | node.role == worker |
| 节点标签 | node.labels.mem == high |
| 节点主机名 | node.hostname == node-01 |
| 引擎标签 | engine.labels.os == linux |
偏好的典型场景:跨机房/可用区部署时,用spread=node.labels.zone让副本尽量分散到不同zone,避免单zone故障时所有副本都挂。
配置与密钥管理(configs / secrets)
Swarm内置了配置和敏感信息的管理,不需要把配置文件bake进镜像、也不用靠环境变量传密码。
- config:存储非敏感配置(如nginx.conf),以文件形式挂载到容器内。
- secret:存储敏感信息(如数据库密码、TLS证书),加密存储在Raft日志里,只有被授权的服务才能读取,挂载到容器的
/run/secrets/目录下(tmpfs,不落盘)。
1 | 创建 secret |
在Compose文件里:
1 | services: |
config和secret更新后不会自动生效——需要docker service update重新挂载(或用版本化命名,如nginx_conf_v2,然后更新服务指向新版本)。
健康检查
Swarm可以在服务级别配置健康检查,决定容器是否”真正可用”。不健康的容器会被停掉并重新调度。
1 | docker service create --name web \ |
| 参数 | 含义 |
|---|---|
--health-cmd |
检查命令,返回0为健康、返回1为不健康 |
--health-interval |
检查间隔(默认30s) |
--health-timeout |
单次检查超时(默认30s) |
--health-retries |
连续几次不健康才判定为故障(默认3) |
--health-start-period |
容器启动后的宽限期,期间失败不计入retries |
健康检查在滚动更新时尤其关键——配合update_config.monitor,Swarm会等新容器健康检查通过后才继续更新下一批,避免一次性把所有副本换成有问题的版本。
网络与负载均衡
overlay 网络
Swarm集群中跨主机的容器通信靠overlay网络。docker swarm init时会自动创建一个名为ingress的overlay网络用于Routing Mesh,用户也可以自建:
1 | docker network create --driver overlay --subnet 10.1.0.0/16 mynet |
overlay网络基于VXLAN隧道,把不同宿主机上的容器虚拟到同一个二层网络里,容器之间可以直接用服务名互访——和《Docker进阶篇》讲的自定义bridge的DNS解析是同一个道理,只是扩展到了跨主机场景。
Routing Mesh(路由网格)
Swarm内置的负载均衡机制。原理:服务发布端口后,集群中每个节点都会监听这个端口,不管请求打到哪个节点、该节点上有没有这个服务的容器,都会被自动转发到实际运行该服务的某个副本上。
1 | 客户端请求 → 任意节点:80 → Routing Mesh → 某个运行web容器的节点 |
这意味着可以把任意节点IP挂到负载均衡器(如Nginx、LB)的后端,不必关心服务具体跑在哪——Swarm自己做了一层内部的四层负载均衡。
Stack 与 deploy 配置
Stack把Compose文件部署到Swarm集群。和单机docker compose up不同,docker stack deploy走的是Swarm调度,deploy字段(replicas、update_config、resources等)会完整生效。
1 | 部署(-c 指定 compose 文件,my_stack 是栈名) |
Stack会自动为栈创建一个overlay网络(名为栈名_default),栈内服务默认都接在上面。如果Compose文件里声明了自定义网络(如net: driver: overlay),也会自动创建。
Stack的核心价值在于声明式 + 一键部署:所有服务的镜像、副本数、更新策略、网络、卷都写在一个YAML文件里,docker stack deploy一条命令搞定。更新时改YAML后再执行同一条命令就行,Swarm会自动做差异化的滚动更新。
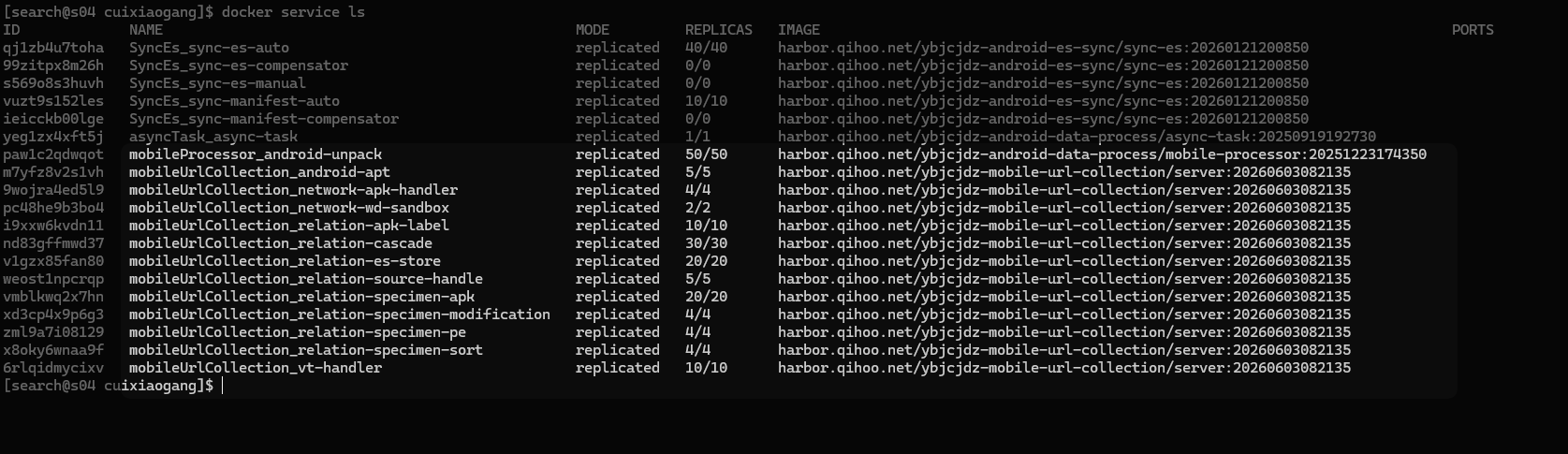
下面是一个真实的 Stack 示例(样本溯源系统),由 12 个微服务组成,同一镜像通过环境变量 SUPERVISOR_CONF_NAME 切换为不同角色,各服务按业务负载设置不同副本数:
1 | version: '3.7' |
这个 Stack 体现了几个实践要点:
- 同一镜像、多角色:所有服务用同一个镜像,通过
SUPERVISOR_CONF_NAME环境变量让容器内的 Supervisor 加载不同的进程配置,实现”一个镜像跑多种服务”。升级时只需更新一个镜像 tag,所有服务统一升级。 - 按负载定副本数:高吞吐的服务(如
relation-cascade: 30、relation-specimen-apk: 20)给更多副本,低负载的(如network-wd-sandbox: 2)只给少量副本,精细控制资源。 - 一键部署:
docker stack deploy -c relation.yml relation一条命令把 12 个服务全部拉起来,扩缩容只需改replicas再重新 deploy。
stack 常用命令
| 命令 | 作用 |
|---|---|
docker stack deploy -c xxx.yml 栈名 |
部署或更新栈 |
docker stack ls |
列出所有栈 |
docker stack services 栈名 |
查看栈内服务 |
docker stack ps 栈名 |
查看栈内所有任务 |
docker stack rm 栈名 |
删除栈(连同服务、网络,卷保留) |
Compose 中 deploy 配置项详解
Compose文件里的deploy字段是Swarm专属的——docker compose up会忽略它,只有docker stack deploy才完整生效。下面列全deploy下的所有配置项:
| 配置项 | 作用 | 示例值 |
|---|---|---|
mode |
部署模式 | replicated(默认)/ global |
replicas |
副本数(仅replicated模式) | 5 |
endpoint_mode |
负载均衡模式 | vip(默认,虚拟IP)/ dnsrr(DNS轮询) |
labels |
服务级别的元数据标签 | com.example.env: prod |
placement |
调度约束与偏好 | 见下方 |
resources |
资源限制与预留 | 见下方 |
update_config |
滚动更新策略 | 见下方 |
rollback_config |
回滚策略(参数同update_config) | 见下方 |
restart_policy |
容器重启策略 | 见下方 |
placement(调度约束)
1 | deploy: |
max_replicas_per_node限制单节点的副本密度,防止一台机器堆太多副本。
resources(资源限制与预留)
1 | deploy: |
limits是天花板——容器不能用超;reservations是地板——节点资源不够这个数就不往上调度。两者配合用:reservations保证调度合理,limits防止单个容器吃光节点资源。
update_config(滚动更新策略)
1 | deploy: |
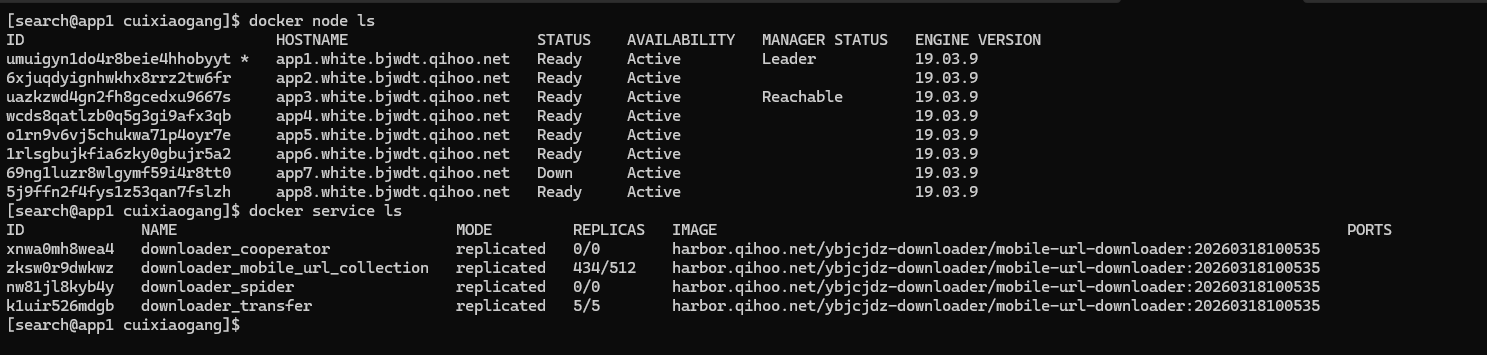
下面是一个生产环境的大规模下载服务栈,重点演示update_config在512 副本场景下的作用——一次性替换全部副本会瞬间重建几百条网络规则,把节点的iptables压垮,所以用parallelism + delay分批慢放:
1 | version: '3.7' |
几个值得注意的点:
parallelism: 8+delay: 3s:512 个副本如果一次性全换,瞬间重建的网络规则会把节点iptables打满。分成每批8个、间隔3秒慢慢滚,是大副本数服务更新时的关键保护。replicas: 0:cooperator和spider把副本数设为0——服务定义保留在栈里,但不实际起容器。需要时docker service scale 栈名_cooperator=10即可秒级拉起,省去重新部署。reservations.memory: 2G:配合前面「异构节点」讲的资源预留,保证每个副本被调度到至少有2G空闲内存的节点,避免OOM。- 自建
overlay网络net:四个服务接在同一个overlay上,跨主机直接用服务名通信,对应前面「overlay 网络」一节。
rollback_config(回滚策略)
参数和update_config完全一致,控制的是docker service rollback或自动回滚时的行为。
restart_policy(重启策略)
1 | deploy: |
注意deploy.restart_policy和顶层的restart不是一回事——restart是docker compose up用的,restart_policy是Swarm用的。
Swarm vs Kubernetes
Swarm和K8s都是容器编排工具,解决的是同一类问题——把容器调度到集群里、管理副本、滚动更新、服务发现。但定位和复杂度差别很大。
| 对比项 | Docker Swarm | Kubernetes(K8s) |
|---|---|---|
| 定位 | Docker原生,轻量编排 | 生产级、工业标准编排平台 |
| 安装复杂度 | docker swarm init一条命令 |
需要单独部署控制面(etcd、apiserver、scheduler等) |
| 学习曲线 | 低,会Docker就会用 | 高,概念多、配置复杂 |
| 调度单位 | Task(一个容器) | Pod(一个或多个容器) |
| 服务定义 | docker service create或Compose文件 |
YAML资源清单(Deployment、Service等) |
| 滚动更新 | 内置,参数简单 | 内置,策略更丰富(蓝绿、金丝雀可扩展) |
| 自愈能力 | 有,容器挂了会重新调度 | 有,且更精细(健康检查、就绪探针等) |
| 扩展性 | 适合中小规模(几十到上百节点) | 支持数千节点级别 |
| 生态 | 相对封闭,社区萎缩 | 极其丰富(Helm、Istio、Prometheus等) |
| 适用场景 | 团队小、集群不大、快速上手 | 大规模生产、微服务治理、多租户 |
一句话:Swarm胜在简单,K8s胜在强大。小团队、中等规模、不想引入太多复杂度时Swarm够用;一旦规模上去、需要精细的调度策略和丰富的生态,K8s基本是唯一选择。目前行业趋势是K8s已经成为事实标准,Swarm的使用在逐年减少。
K8s 核心概念速览
K8s的完整体系需要独立成篇,这里只列最核心的几个概念,建立一个基本的认知框架,方便后续深入。
| 概念 | 作用 | 和Swarm的对应关系 |
|---|---|---|
| Pod | K8s最小调度单位,一个Pod里可以有1~N个容器,共享网络和存储 | 对应Swarm的Task(但Task只有一个容器) |
| Deployment | 管理Pod的副本数、滚动更新、回滚 | 对应Swarm的Service |
| Service | 为一组Pod提供稳定的访问入口(虚拟IP + DNS),做负载均衡 | 对应Swarm的Routing Mesh + 服务名DNS |
| Namespace | 逻辑隔离,同一集群内划分多个虚拟空间(如dev/staging/prod) | Swarm无对应,Stack只是分组不隔离 |
| Ingress | 七层(HTTP)路由入口,把外部域名/路径映射到集群内的Service | Swarm只有四层负载均衡(Routing Mesh) |
| ConfigMap / Secret | 配置和敏感信息管理,与容器解耦 | 对应Swarm的configs/secrets |
| Node | 集群中的工作机器 | 和Swarm Node一致 |
K8s的架构也是Master(控制面)+ Worker(数据面),控制面组件包括etcd(存储)、kube-apiserver(API入口)、kube-scheduler(调度器)、kube-controller-manager(控制器),Worker上跑kubelet和kube-proxy。比Swarm的Manager/Worker拆得更细、各司其职。
K8s的所有操作都是声明式的:写YAML描述”期望状态”,kubectl apply提交给apiserver,控制器持续驱动”当前状态”向”期望状态”收敛。和Swarm的docker stack deploy思路一致,但K8s的资源类型(CRD可自定义扩展)远比Swarm丰富。
K8s的安装、部署和实操内容较多,留给独立的篇章记录。