Linux服务器网络限流Traffic Control
项目介绍
业务通过接收URL,对URL中的资源进行下载(支持分片、代理等功能)。服务器存在多个集群,这些集群共同消费一个RabbitMQ,每个集群下载的文件速度和数量取决于当前集群下的机器状态。比如万兆网卡机器的下载速度肯定要远远高于千兆网卡机器的下载速度。同时,不同集群使用docker-swarm进行服务部署,便于管理、维护。
集群情况
- A机房
- 1集群:6台万兆网卡机器
- 2集群:12台千兆网卡机器
- B机房
- 3集群:8台万兆网卡机器
- C机房
- 4集群:16台千兆网卡机器
- D机房
- 5集群:22台千兆网卡机器
问题说明
- 业务日常运行时没有问题,但每天在一个固定时间下,上游推送的URL会激增,导致所有集群的上游出现网络峰值
- A机房的带宽费用跟峰值挂钩(每个机房的签约合同不一样,带宽费用的结算方式也不一样),其他机房则没有这个问题
- URL队列中的数据不能长期积压,否则有失效的风险(一般的URL都有时效性)
通过上面问题的汇总,需要我们单独的对 “1集群” 的6台万兆网卡机器做独立的限流,保证峰值不超过阈值,同时还不能对数据的消费造成较大的影响
方案分析
第一种方案
对业务进行改造,使用docker-swarm部署时,通过环境变量(environment)的方式,为不同的集群传入一个不同的阈值,容器内的业务在运行过程中,实时查看当前网卡的近期下载速度,然后限流
存在的问题
- 容器内服务直接获取到宿主机的网卡信息,可以通过以下方式解决
- 将网卡信息/proc/net/dev通过映射(volumn)的方式挂载到容器中,然后业务可以直接读取该文件既可
1 | eth2: 1077943200252635 745415886069 0 366195226 0 0 0 4915158 138918837199706 253225064446 0 0 0 0 0 0 |
- 需要对不同的集群设置不同的阈值,导致每个集群的docker-compose.yaml的配置不一样,不方便管理
第二种方案
请求运维在机房端(比如交换机)增加限制,以实现限流的目的
存在的问题
- 机房端直接限制会增加网络丢包的风险,因为一般的交换机内存/处理器的配置都要远远低于服务器,它们限流的方式主要是监控数据包,如果数据包超过阈值,则直接丢弃
- 交换机直接限流,会造成后续维护的困难,有可能在业务交替、机器替换时出现问题
第三种方案
在服务器上使用Traffic Control(流量控制)来限流,这也是我们选择的方案
Traffic Control介绍及使用
Traffic Control原理
- Traffic Control通过令牌桶算法,以固定速率生成令牌
- 每个数据包需要消耗一定数量的令牌
- 而当令牌桶中没有令牌时,数据包会被排队等待,当队列满(默认1MB)后才开始丢包
基于上述的概念,理论上就可以通过调整令牌的生成速率和桶大小,来精确的控制流量了。
相关组件
- qdisc (Queueing Discipline):决定流量如何排队、发送和丢弃
- class (类):将流量分类到不同的优先级或子队列
- filter (过滤器):匹配流量的特定属性(如IP、端口等)
问题及解决方案
基于Traffic Control原理,它依然存在如下问题:
- Traffic Control只能控制“发包”,而不能直接控制“收包”,这也就说明,我们无法控制下行带宽的速率
- 当队列满时,也会发生丢包的情况,我们应该如何避免丢包情况的发生
解决问题一
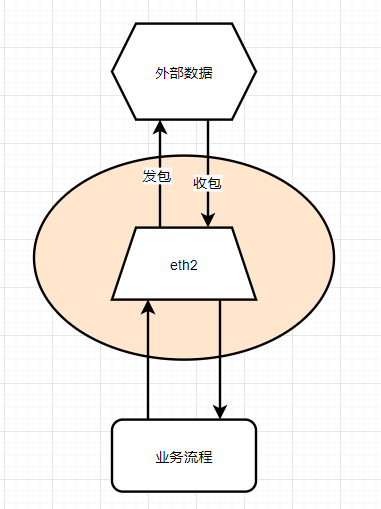
解决Traffic Control只能控制“发包”的问题,我们在物理网卡eth2和业务之间,增加一个虚拟网卡ifb2,让eth2将数据包通过filter重定向到ifb2上,然后业务使用虚拟网卡ifb2接收数据时,对于ifb2来说,这些数据包就是“发包”流程了,Traffic Control可以直接控制
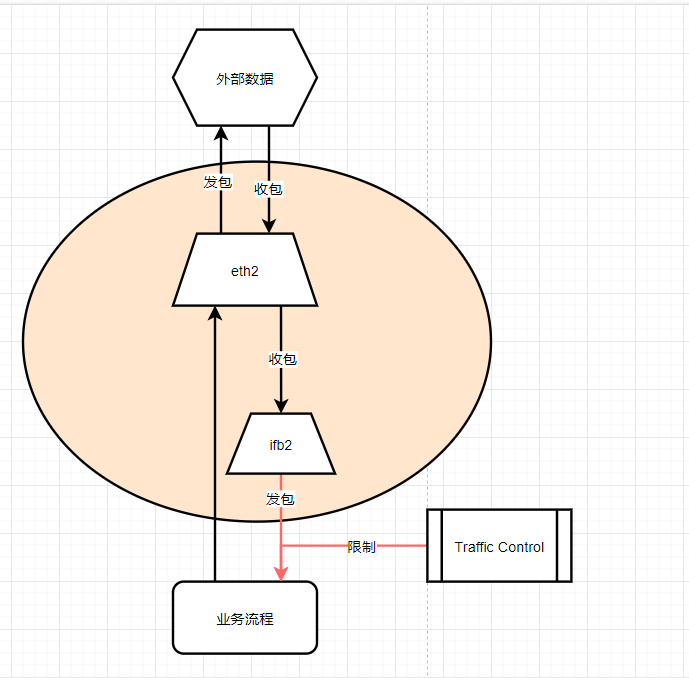
解决问题二
我们可以适当的增加队列的大小,来尽可能的降低丢包的可能性
使用及配置
1 | # 安装 |
效果校验
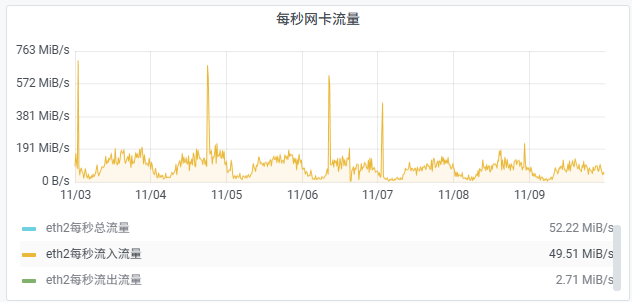
通过上图发现,峰值幅度明显降低
后记
Traffic Control工具复杂且难以把控,可以使用wondershaper来限制网卡流量,这个命令的底层也是使用的Traffic Control,不过它只需要一条命令就够了
1 | wondershaper -a eth2 -d 4000mbit -u 0 |